В этой статье маг Ольга Васильева отвечает на вопрос «Как предсказать конверсию?».

Команда Яндекс.Директа рассказала, как сервис научился предсказывать конверсии и экономить бюджеты в сетях. Оказалось, что Директ автоматически снижает ставки рекламодателей в зависимости от прогнозируемых конверсий.
В РСЯ и внешних сетях есть автоматический контроль качества кликов и конверсий. Его начали внедрять больше года назад, и он все еще совершенствуется.
В чем суть: на площадках с низкоконверсионным трафиком клики стоят дешевле. Алгоритмы защиты от перетрат позволяют Директу сохранять для каждого рекламодателя адекватную среднюю цену конверсии. А автоматическая корректировка ставок помогает сэкономить деньги в тех случаях, когда полезность показа рекламы оказывается ниже средних показателей для конкретного рекламодателя.
Внутри системы это просто поправка к ставке – понижающий коэффициент, который меняется в зависимости от результатов прогноза вероятности конверсии: за полную стоимость рекламодатель покупает только наиболее эффективные переходы по объявлениям.
У 40% самых высококонверсионных кликов коэффициенты корректировки варьируются от 0,8 до 1. Для 15% кликов с самой низкой вероятностью конверсии исходная ставка рекламодателя автоматически уменьшается минимум вдвое, а в отдельных случаях — в десять и более раз (то есть срабатывают коэффициенты =



Общее правило эффективной контекстной рекламы — ставки должны быть пропорциональны конверсии. Мало ключевых слов имеют достаточное количество кликов для достоверной статистики. Для низкочастотных запросов расчет конверсии в лоб будет чреват проблемами. Для большинства фраз в статистике по одному-двум кликам и коэффициент конверсии равен нулю. А если один клик и одна транзакция, равен 100%.
Для низкочастотных фраз нужно прогнозировать конверсию. Инструменты для прогнозирования:
— сторонние оптимизаторы конверсии. На основе собственных алгоритмов они прогнозируют конверсию и управляют ставками.
— машинное обучение. На курсе по Excel , в бонусных уроках, мы рассказываем, как можно прогнозировать конверсию, используя дерево решений bigml.com.
— метод статистического пуллинга, описанный Андреем Белоусовым. Подробнее в статье на SearchEngines .
Герой прошлой статьи Петя использует метод Андрея Белоусова и прогнозирует конверсию в Excel. Рассмотрим метрики, которые ему помогут.
Прогноз коэффициента конверсии (CR_прогноз) — прогнозируемая конверсия для сущностей, по которым нет достаточной статистики: кампании с малым количеством кликов, группы объявлений, фразы.
Метод статистического пуллинга, описанный Андреем Белоусовым
CR_прогноз = (Конверсии + A) / (Клики + A/M )
где M — показатель конверсии группы, A — число, которое отражает степень сходства ключевых слов в группе.
CR_прогноз = (Конверсии + 1)/(Клики + 1/M )
Петя рассчитал прогноз конверсии для своих ключевых фраз, и наше ожидание конверсии стало гораздо более адекватным:

Расхождение фактического и прогнозного коэффициента конверсий для запросов с малым количеством кликов
Прогнозная стоимость заказа (СРО_прогноз) — прогнозируемая стоимость заказа для сущностей, по которым нет достаточной статистики.
CPC фактический (по конкретному ключевому слову) / CR_прогнозный (по конкретному ключевому слову)
Петя спрогнозировал CPO по своим кампаниям и удивился. Он отфильтровал ключевые слова по колонке CPO_прогноз. Оказалось, по многим ключевым словам получился сильно завышенный CPO. По этим фразам нужно снижать ставки, скорее всего, они принесут дорогие заказы.

CPO_прогноз помогает найти фразы, которые работают в убыток
Еще Петя обнаружил, что часть фраз работает очень эффективно. По ним нужно повысить ставки, чтобы получать больше кликов и заказов.

CPO_прогноз помогает найти эффективные фразы, по которым нужно увеличить ставку
Прогнозная стоимость заказа помогает выявить фразы, которые потенциально работают в убыток из-за завышенной стоимости клика в исследуемом периоде. Если мы давно не меняли ставки и выявили большие отклонения метрики CPO_прогнозный, значит нам надо изменять ставки.
Предельная стоимость заказа (СРО_предельный) — максимальный CPO, который получится, если будет списываться выставленная в Директе ставка, без снижения (амнистии – про это далее) и конверсия будет соответствовать CR_прогноз.
Ставка по ключевому слову / CR_прогноз (по конкретному ключевому слову)
СРО_предельный дополняет метрику СРО_прогноз. Петя отсортировал список от максимального CPO_предельный к минимальному. Он нашел ключевые слова, по которым завышена ставка. Если у фразы высокий CPO_предельный и СРО_прогнозный, нужно понизить ставку или выключить фразу.
Если CPO_предельный ниже CPO_прогнозный, это значит, что ставки уже были понижены от исторического периода.

По фразам, у которых высокий CPO_прогноз и CPO_предельный, нужно снижать ставки. По фразам, скорее всего, будут дорогие конверсии
Прогнозная стоимость клика (СРС_целевой) — целевая стоимость клика по ключевому слову, когда мы спрогнозировали для него конверсию, и знаем CPO_целевой.
СРО_целевой / CR_прогнозный (по конкретному ключевому слову)
Петя рассчитал CPC_целевой для фраз, по которым нужно снижать ставки. На некоторые фразы ставку нужно снижать в 20 раз или отключать. Эти фразы работают в убыток.

CPO_целевой помогает выставить ставки, чтобы реклама давала прибыль
Метрика, подслушанная Максом в Яндексе
Коэффициент амнистии — коэффициент, который показывает, насколько ставка отличается от стоимости клика. Точно рассчитывать метрику можно, зная в какое время какая ставка была установлена. Еще важно помнить про модификаторы ставок по времени суток. Но исторически установленные ставки в рекламных системах посмотреть, к сожалению, нет возможности. Поэтому часто приходится пользоваться допущениями, что в конкретный промежуток времени стояла определенная ставка.

Петя рассчитал коэффициент амнистии
Коэффициент амнистии помогает рассчитать ставку, чтобы добиться прогнозной стоимости клика.
Средневзвешенный коэффициент амнистии — коэффициент, который показывает, насколько ставка отличается от стоимости клика по всему аккаунту.
Коэффициент амнистии по каждому слову * Число кликов по слову / Общее число кликов
Средневзвешенный коэффициент амнистии похож на число Пи. Эта величина показывает, насколько ставка выше, чем фактическая стоимость клика. Пример: Пете нужно получить целевую стоимость клика в 15 рублей. Он рассчитал средневзвешенный коэффициент амнистии по аккаунту — 2,2. Петя может поставить ставку в 2,2 раза больше, чтобы достичь стоимости клика в 15 рублей.
Метрика для исследования роста конверсии
Шаг конверсии по минимальному шагу торгов — метрика говорит о том, как у нас должна измениться конверсия, чтобы мы поднялись на один шаг торгов в нашем текущем аукционе.
У нас есть целевой CPO, минимальная стоимость клика, минимально рентабельная конверсия из первой части статьи. Увеличим минимальную стоимость клика на 1 рубль и пересчитаем показатели.

При увеличении стоимости клика на 1 рубль минимальная конверсия должна вырасти минимум на 0,2%, иначе реклама будет убыточна
Петя посчитал, насколько должна измениться конверсия, чтобы он увеличил ставку на 1 рубль. Чтобы при этом реклама работала в плюс, прогнозируемая конверсия по ключевому слову должна увеличится на 0,2%. Далее он смотрит на аккаунт и находит ключевые слова, по которым разница в ставках составляет 5 рублей, но при этом прогнозируемая конверсия различается всего на 0,3%. Петя сразу понимает, что ставки расставлены некорректно.
Самая суть цепочек рекламных каналов вызывает непреодолимое желание узнать, что вероятнее всего произойдет дальше в цепочке. Будет конверсия или нет?
Но это похвальное стремление часто утыкается в проблему. Если пытаться удерживать количество ложно-положительных результатов в разумных рамках, количество истинно-положительных не впечатляет. Как следствие — результаты анализа зачастую не позволяют нам принимать адекватные управленческие решения. Адекватное прогнозирование требует больше данных, чем просто короткие цепочки пользовательских прикосновений к каналам. Но это вовсе не значит, что задачу стоит бросать.

В этой статье мы расскажем вам немного о серии экспериментов по разработке алгоритма прогнозирования конверсии. Эта статья — продолжение двух предыдущих на схожую тематику. Вот первая, Вот вторая.
Для LSTM существует огромное количество отличных материалов по созданию системы, которая предсказывает значения временных рядов и буквы в словах. В нашем случае задача была еще проще, на первый взгляд.

Рис.1. Обработка грубых данных для удаления слишком коротких и расщепления слишком длинных цепочек.
Наша цель — определить комбинацию касаний, которая максимизирует вероятность конверсии по всей базе потребителей для цепочек выбранной длины. Для этого мы выделяем слова (цепочки) требуемой длины из всей выборки. Если цепочка длиннее заданной, она расщепляется на несколько цепочек желаемой длины. Например — (1,2,3,4) -> (1,2,3), (2,3,4). Процесс обработки изображен на рисунке 1.
Ключевое наблюдение 1
Однородные цепочки в этом исследовании бесполезны. У них конверсия зависит только от длины цепочки и номера канала, классификатор для них строится логистической мультирегрессией с двумя факторами. Категориальный фактор — номер канала, и числовой — длина цепочки. Получается довольно прозрачно, хотя и бесполезно, потому что достаточно длинные цепочки в любом случае подозрительны на конверсию. Поэтому их можно не рассматривать вообще. Тут, надо отметить, что размер выборки существенно сокращается, потому что обычно где-то 80% всех цепочек однородные.
Ключевое наблюдение 2
Можете выбросить все (принципиально) неактивные каналы, чтобы ограничить объем данных.
Ключевое наблюдение 3
Для любой цепочки вы можете применить one-hot кодирование. Это устраняет проблему, которая может возникнуть, если маркировать каналы как числовую последовательность. Например, выражение 3 — 1 = 2 не имеет смысла, если числа это номера каналов (Рис.2.).
Кроме всего прочего, мы попытались закодировать цепочку еще некоторым количеством странных способов, которые строились на различных предположениях о природе цепочек. Но так как это нам ничем не помогло, мы об этом говорить не будем.

Рис.2. Второе преобразование данных. Удалите все однородные цепи, примените one-hot кодирование.
Для разных вариантов кодировки цепочек были испробованы такие инструменты для классификации:
- LSTM
- Multiple LSTM
- Многослойный персептрон (2,3,4, слоя)
- Random Forest
- Gradient Boosting Classifier(GBC)
- SVM
- Deep Convolutional Network (c 2 слоями, чисто на всякий случай)
Параметры всех моделей оптимизировались с помощью алгоритма Basin-hopping. Результат оптимизма не вызывал. AUC ROC поднялся до 0.6, но в нашем случае этого было явно недостаточно.
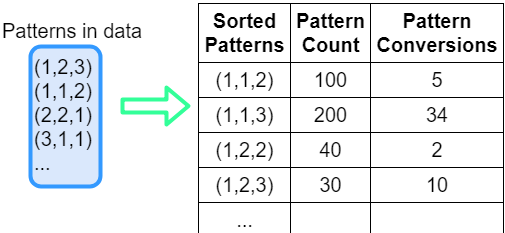
Рис.3. Сортировка и подсчет шаблонов цепочек
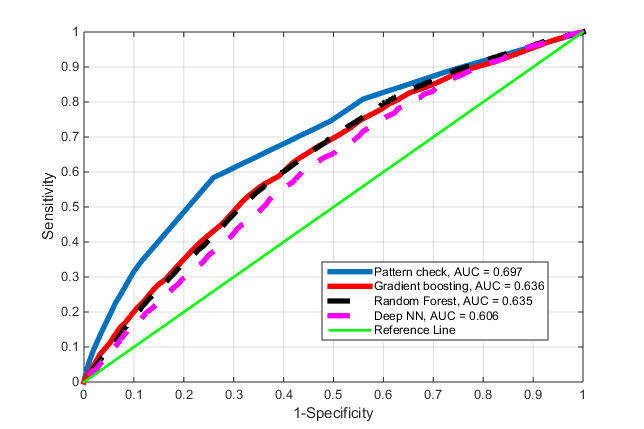
Рис.4. ROC кривые для разных классификаторов.
Для нашего нового метода AUC = 0.7. Это уже что-то. Не прям победа, но уже далеко не подброс монетки. Замечание. Этот метод можно реализовать и без использования one-hot, как тут и описано для понятности, но при желании развить успех, он уже может потребоваться.
Читайте также:
